
機能説明
指定したキーワードでGoogle検索した際に上位表示されているサイトのURLを取得するツールです。
コード全体
下記コードをColaboratoryに貼り付け、実際の動作を確認してください。
◆コード
from bs4 import BeautifulSoup
import requests
import urllib.parse
from time import sleep
keyword = 'パソコン'
keyword = urllib.parse.quote(keyword)
url = 'https://www.google.co.jp/search?sourceid=chrome&ie=UTF-8&num=15&q='
url = url + keyword
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"}
data = None
request = urllib.request.Request(url, data, headers)
response = urllib.request.urlopen(request)
html = response.read()
sleep(1)
soup1 = BeautifulSoup(html,'html.parser')
sites = soup1.select('.yuRUbf > a')
for site in sites:
site_url = site.get('href')
print(site_url)
◆出力結果
https://kakaku.com/pc/ https://www.pc-koubou.jp/ https://www.amazon.co.jp/%E3%83%91%E3%82%BD%E3%82%B3%E3%83%B3/b?ie=UTF8&node=2188762051 https://www.biccamera.com/bc/i/topics/notebook/index.jsp https://search.rakuten.co.jp/search/mall/%E3%83%8E%E3%83%BC%E3%83%88%E3%83%91%E3%82%BD%E3%82%B3%E3%83%B3/ https://www.nojima.co.jp/support/koneta/48370/ https://www.mouse-jp.co.jp/ https://jp.ext.hp.com/notebooks/personal/ https://www.yodobashi.com/category/19531/ https://www.dospara.co.jp/ https://www.nec-lavie.jp/ https://pc.watch.impress.co.jp/ https://used.sofmap.com/r/category/pc
機能の説明
1.
from bs4 import BeautifulSoup import requests import urllib.parse from time import sleep
ライブラリをインポートしています。
それぞれ、以下のような機能を持っています。
requests:Http通信を行います
urllib.parse:URLエンコードやデコードを行います
BeautifulSoup:HTML からデータを抽出します。
2.
keyword = 'パソコン' keyword = urllib.parse.quote(keyword)
キーワードを指定し、日本語のキーワードをURLエンコードします。
こうすることで、日本語を含むURLを処理することができるようになります。
3.
url = 'https://www.google.co.jp/search?sourceid=chrome&ie=UTF-8&num=15&q='
Googleで検索するためのURLを用意します。
「q=」の後ろにキーワードを指定すると、そのキーワードでGoogle検索することを意味します。
4.
url = url + keyword
検索用のURLとキーワードを結合して、再びURLに代入します。
5.
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"}
data = None
request = urllib.request.Request(url, data, headers)
response = urllib.request.urlopen(request)
html = response.read()
requestのライブラリを使用して、Google検索の検索結果を取得します。
なお、ここは深く理解する必要はありません。
「url」を指定すると、そのページの結果(HTMLコード)が「html」に代入されるということだけ理解していれば大丈夫です。
6.
sleep(1)
結果を確実に取得できるよう1秒ほど待ちます。
7.
soup1 = BeautifulSoup(html,'html.parser')
取得したHTMLコードからBeautifulSoupで扱えるようBeautifulSoup用のオブジェクトを生成します。
8.
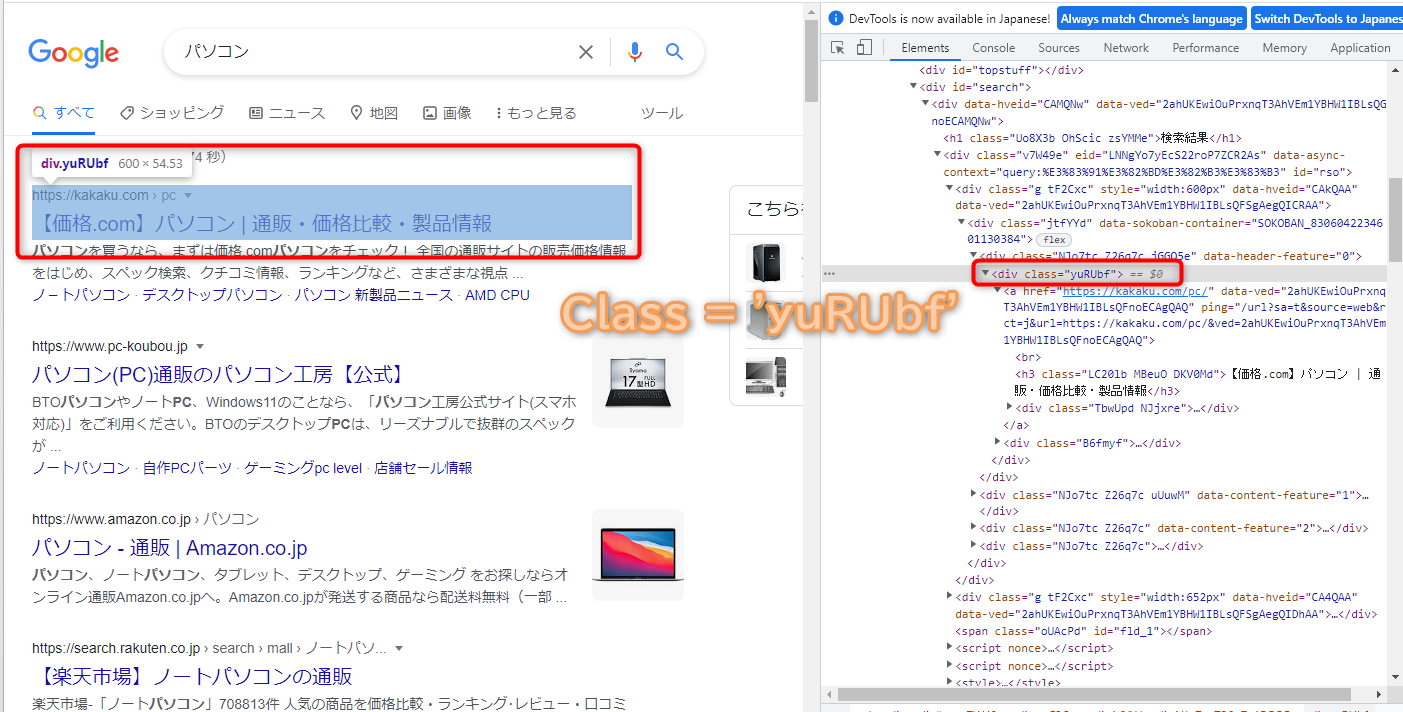
sites = soup1.select('.yuRUbf > a')
BeautifulSoupのselectメソッドを使用すると、クラス名や属性などを指定することによって、それに該当する部分をリスト形式で取得することができます。
上記の場合、クラス名が「yuRUbf」の「a」タグの内容をリスト形式で取得することができます。
なお、このクラス名はChromeブラウザで調べることができるのですが、ここでは「yuRUbf」を指定すれば良いと理解しておいてください。
(このクラス名はGoogleの仕様変更により変わる場合があります。)
ちなみに、Chromeブラウザで調べると以下のようになっていることがわかります。
9.
for site in sites:
BeautifulSoupのselectメソッドで取得したリストの要素数分、繰り返し処理を行います。
10.
site_url = site.get('href')
BeautifulSoupのselectメソッドでhref属性の値(URL)を取得します。
11.
print(site_url)
URLを表示します。
