
ライブラリを実際に使ってみたいと思います。
ネットビジネスで最もよく使われるテクニックのひとつとしてWebスクレイピングというものがあります。これはWebサイトから特定の情報を自動的に抽出する方法を指します。
Webスクレイピングは、商品情報や価格、レビューなどの情報を収集するのに役立ちます。また、ニュースやブログ記事などのコンテンツを自動的に生成するのにも使われます。
Webスクレイピングで使う「Cheerio」というライブラリは、HTMLを解析するためのJavaScriptライブラリです。使いやすい機能を備えており、初心者でも簡単にWebスクレイピングを実行できます。
今回はこの「Cheerio」を使って、ライブラリの使用方法を学習します。
ライブラリの追加
ライブラリを使用するためにはライブラリを追加する必要があります。
次の手順で「Cheerio」ライブラリを追加してください。
GASの開発画面でライブラリの「+」をクリックします。
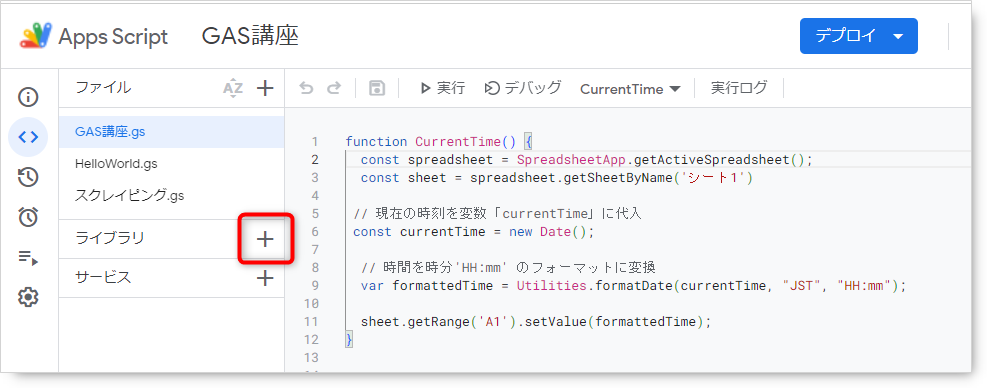
スクリプトIDにライブラリを特定するIDを入力して、検索ボタンをクリックします。
なお、スクリプトIDはライブラリごとに決まっています。「Cheerio」のスクリプトIDは以下です。
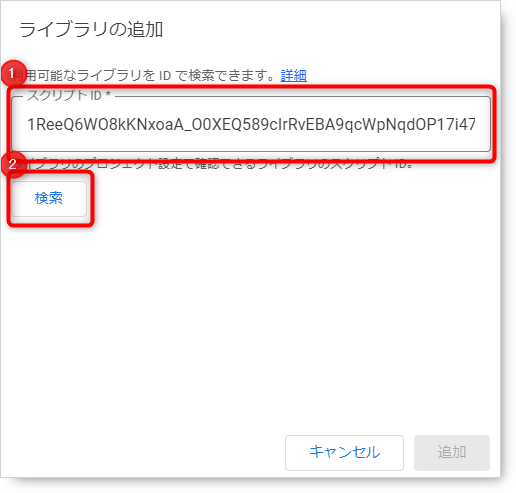
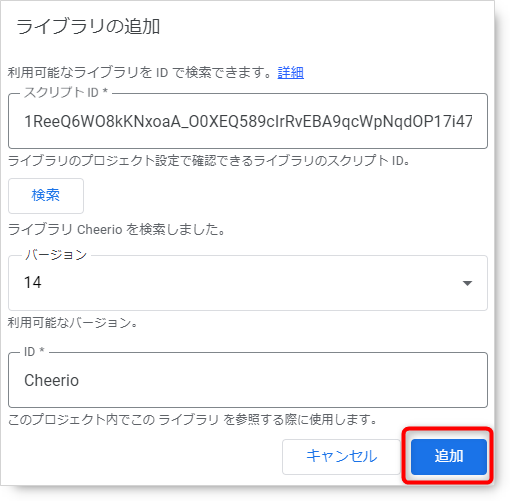
検索結果が表示されます。バージョンや参照IDを変更できますが基本的にそのままで大丈夫なので追加ボタンをクリックします。
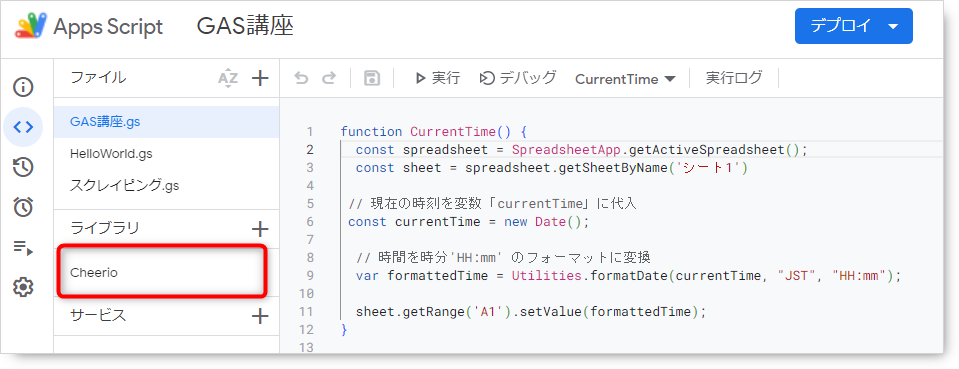
以上の手順でライブラリが追加され、ライブラリを使用できるようになります。
Cheerioの使い方
Cheerioの使い方を解説します。
以下のようなHTMLがあるとし、そこから要素を取得する方法を考えてみたいと思います。
<html>
<body>
<h1>タイトル</h1>
<h2>見出し1</h2>
<ul>
<li class="item">Item 1</li>
<li class="item">Item 2</li>
<li class="item">Item 3</li>
</ul>
<a href="https://yahoo.co.jp">ヤフー</a>
</body>
</html>
このHTMLをCheerioで処理するために、このHTMLをCheerioに読み込む必要があります。
これは以下のコードで実装できます。
const html = ` <html> <body> <h1>タイトル</h1> <h2>見出し1</h2> <ul> <li class="item">Item 1</li> <li class="item">Item 2</li> <li class="item">Item 3</li> </ul> <a href="https://yahoo.co.jp">ヤフー</a> </body> </html> `; const $ = Cheerio.load(html);
このコードでは、HTMLの内容を変数のhtmlに代入して、その値をCheerioのload関数を使ってCheerioオブジェクトとして読み込み変数の$に代入しています。
Cheerioでは慣例として、変数に$を使用しますが、通常の変数と同様です。
以上で、HTMLをCheerioで解析する準備ができ、HTMLの内容を次のようにタグやクラス名を使って選択できるようになります。
$('h1') // <h1>タグを選択
$('.item') // classが"item"の要素を選択
$('a') // <a>タグを選択
選択した要素は、以下のようにテキストや属性を取得することができます。
■テキスト取得: .text() を使って要素のテキストを取得できます。
const title = $('h1').text();
■属性取得: .attr() を使って要素の属性を取得できます。
const link = $('a').attr('href');
また要素が複数ある場合は、.each() を使って各要素に対して関数を繰り返し実行できます。
$('.item').each(function(index, element) {
console.log($(element).text());
});
Cheerioの動作を確認する
Cheerioの使い方を踏まえた上で実際の動作を確認します。下記コードを貼り付けて実行してください。
◆コード
function cheerioSample() {
const html = `
<html>
<body>
<h1>タイトル</h1>
<h2>見出し1</h2>
<ul>
<li class="item">Item 1</li>
<li class="item">Item 2</li>
<li class="item">Item 3</li>
</ul>
<a href="https://yahoo.co.jp">ヤフー</a>
</body>
</html>
`;
// HTMLをCheerioオブジェクトとして読み込む
const $ = Cheerio.load(html);
// h1タグのテキストを取得
const title = $('h1').text();
console.log(title);
// aタグのhref属性を取得
const link = $('a').attr('href');
console.log(link);
// itemクラスを各要素ごとに処理する
$('.item').each(
function(index, element) {
console.log($(element).text()
);
});
}
◆実行結果
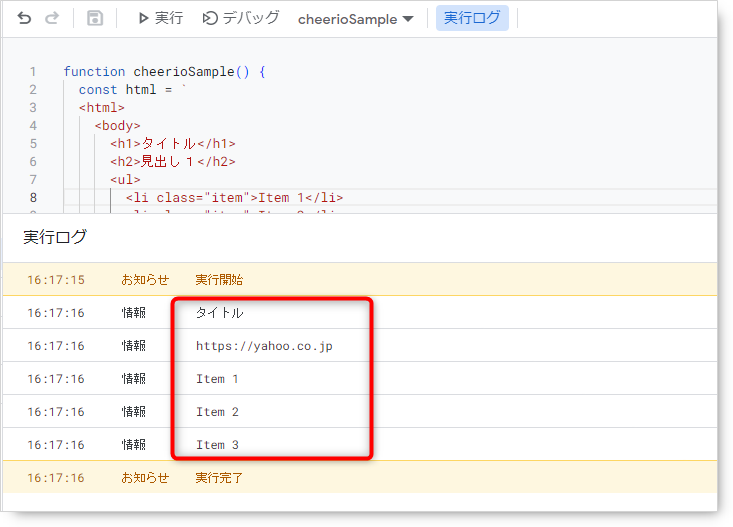
機能の説明
1.
// h1タグのテキストを取得
const title = $('h1').text();
console.log(title);
$(‘h1’)でh1タグを選択し、text()を使ってそのテキストを取得します。
結果として「タイトル」という文字列が取得されました。
2.
// aタグのhref属性を取得
const link = $('a').attr('href');
console.log(link);
$(‘a’)でaタグを選択し、attr(‘href’)を使ってそのhrefの属性(リンク先)を取得します。
結果として「https://yahoo.co.jp」というリンクが取得されました。
3.
// itemクラスを各要素ごとに処理する
$('.item').each(
function(index, element) {
console.log($(element).text()
);
});
$(‘.item’)でHTML内のすべてのを.itemの要素を選択し、それぞれの要素に対して関数を実行します。
この関数の引数として、現在の要素のインデックス(index)と要素の内容(element)が渡されます。
関数内では、$(element)で要素を選択して、text()を使ってそのテキストを取得します。
以下に、コードの説明をよりわかりやすくするために、いくつかの補足説明を追加します。
$('.item')は、CSSセレクタを使用して要素を取得します。この場合、.itemクラスを持つすべての要素が取得されます。each()メソッドの引数として渡される関数は、無名関数です。無名関数とは、名前のない関数のことです。indexは、現在の要素のインデックスを表します。インデックスは、要素の配列の要素番号です。elementは、現在の要素の内容を表します。要素の内容とは、要素のHTMLコードです。text()メソッドは、要素のテキストを取得します。
この書き方は理解が難しいかもしれませんが、「Cheerio」では複数の要素を扱う場合には、このように書くということで、このままひとつの塊として考えてください。
そして、ひとつひとつの内容を確認するためにはelementということを理解しておけば大丈夫です。
練習問題
1.
h2タグの内容(「見出し1」という文字列)を取得して、Console.logで出力してください。
2.
aタグのテキスト部分(ヤフーと記載のある部分)を取得して、Console.logで出力してください。
